
By now you probably know about GraphQL, or at least you might have read or heard that name somewhere. Wikipedia says that “GraphQL is an open-source data query and manipulation language for APIs, and a runtime for fulfilling queries with existing data”. If that doesn’t say much to you, or if you have read about GraphQL before but didn’t understand very well what it is, then this article is for you. Its purpose is to try – again – to explain what GraphQL is, its advantages and disadvantages, from the perspective of a Delphi (and also TMS XData) developer.
What is GraphQL?
There are plenty of articles explaining what GraphQL is. The official site, the Wikipedia article, tutorials here and there. So I will try to not be repetitive here and explain it my way, converting the points I was most confused of when I was learning about it. First of all:

- GraphQL is NOT a framework or programming library;
- GraphQL is NOT a server application;
- GraphQL is NOT a database server or wrapper.
When I first started learning about it, this got me confused as well. What is GraphQL then?
- GraphQL is a SPECIFICATION for a language and a runtime (available here).
In other words, GraphQL strictly specifies a query language and how runtime libraries should “execute” that language. Using a very rough analogy, it’s like a strict specification of SQL, explaining how SQL statements should be parsed and validated, and providing algorithms defining how database servers should execute those SQL and return data.
Of course, then you have several GraphQL implementations, which are indeed libraries in several different languages like Java, .NET, JavaScript, that allow you to create, for example, servers that, through HTTP, allow clients to send such queries and get the response of such query execution in JSON format. But note that even that HTTP communication is not strictly specified. It’s just one of many ways to “execute” a GraphQL document (a text file containing a query in valid GraphQL language).
GraphQL is “strongly typed”
This is one key point of GraphQL. Whatever you are going to do with it, you always start from a “schema”, which specifies all the types available in the language. The following is an example of a GraphQL schema:
type Query {
human(id: Int): Human
}
type Human {
id: Int!
name: String!
homePlanet: String
height: Float
mass: Float
}
The above schema specifies two object types: Query and Human, the fields in each object type, and the type returned for each field. Fields can also have arguments (parameters), also with its specified type (human field in Query type has the parameter id of type Int).
If you are implementing a server that supports GraphQL, you have to define a schema first. If you are writing a client that sends GraphQL queries to a server, those queries must comply with the specified schema. You cannot create a query asking for a type that doesn’t exist. Or a field that doesn’t exist. Or even using a field parameter (argument) of a different data type than the specified.
It’s interesting to note that in a world that dynamic languages are so popular today (JavaScript being the main one), one of the key claims about GraphQL advantages is that it’s strongly typed – something I personally like, as a Delphi developer.
GraphQL documents (queries)
Once the GraphQL schema is defined, clients can write GraphQL documents (queries). In summary, a GraphQL query just lists the fields that we want the values for, and if such fields return objects, the fields of those objects, and on and on at any depth level you want. For example:
{
human(id: 1000) {
name
height
}
}
The query above asks for the value of human field of type Query (implicit by default because of its name), passing the value 1000 for the id parameter. Since human field returns an object of type Human, the query also asks for just fields name and height for such object.
If such query is sent via HTTP to a server implementing GraphQL, the server will execute the query and return its results. A possible result could be something like this:
{
"data": {
"human": {
"name": "Luke Skywalker",
"height": 1.72
}
}
}
You get what you asked for: the result of human field, and the name and height fields of the Human object. It’s also important to explain two things:
- The GraphQL query is NOT a JSON document, even though it looks like one. It’s a GraphQL query, with its specific syntax as defined by the specification.
- The result data IS a JSON document, and the way it is formatted is NOT in the specification. It could be a XML document or whatever other format.
GraphQL and HTTP
GraphQL specification doesn’t say anything about HTTP. That really got me confused at the beginning, because I was reading all around about how GraphQL compares to REST, how it’s a new way to build APIs, etc. But the thing is GraphQL is not about HTTP, but only about the query language and how it should return results, in any format.
But of course, HTTP became the main way of executing GraphQL queries, and JSON end up being the most used format to return the results of such execution. The closest to a standard we have are some guidelines about how to serve GraphQL over HTTP, in the official GraphQL site.
In summary, there are no multiple endpoints: GraphQL queries are sent to a single URL endpoint, either directly in the URL in GET requests:
https://myapi/graphql?query={{human(id:1000){name,height}}
or in a JSON document, in POST requests:
POST /graphql HTTP/1.1
Host: myapi
{
"query": "{{human(id:1000){name,height}}"
}
And the server response is usually a JSON document, as we saw above. It’s also interesting to note that if the GraphQL query is accepted, it always return an HTTP status code 200, even if the query execution fails. If there are errors, they appear inside the JSON document (error format is included in GraphQL specification):
{
"errors": [
{
"message": "Cannot query field \"homePlanet\" on type \"Human\"."
}
]
}
Why GraphQL?
Now that we have quickly covered what GraphQL is, it’s time to learn why it’s beginning to be so widely used.
There are several articles mentioning GraphQL advantages and disadvantages compared to REST, explaining why it’s taking over APIs, directly comparing GraphQL and REST, listing reasons why you should consider a GraphQL server and even how to convince your boss to use GraphQL (despite the awful name – in my opinion – this last one is a nice article about GraphQL).
I will try to summarize what I think are the key reasons. I will also try to compare it with REST and specially with TMS XData – a framework to build REST API servers using Delphi.
Clients choose what to fetch In REST, if you want to retrieve an invoice, you will do something like this:
GET /invoice/10
{
"id": 10,
"total": 152
}
Then, if you want to retrieve the customer of the invoice, you need another request:
GET /invoice/10/customer
{
"id": 115,
"name": "Joe Doe"
}
Of course, your REST server could return customer data inline in the first request, when invoice is requested. But then, what if the client does not want customer data? The server will return more data than the client needs. In GraphQL you write the query asking just the data you want. Either without customer data:
{
invoice(10) {
id
total
}
}
or with customer data:
{
invoice(10) {
id
total
customer {
id
name
}
}
}
And you don’t have to modify your server for that, or create multiple endpoints. Developing client applications with GraphQL, specially mobile and web applications, is a breeze, and performs very well – in a single request you get all the data you need, and only the data you need.
On the other hand, your REST server could implement mechanisms to allow your client to better choose what it needs. That’s what XData does, for example, with the $expand query filter mechanism. When an invoice is request from the client, it comes with minimum customer information (just the id):
GET /invoice/10
{
"id": 10,
"total": 152,
"[email protected]": "customer(115)"
}
but if the client wants full customer information, he can just ask for it using $expand:
GET /invoice/10?$expand=customer
{
"id": 10,
"total": 152,
"customer": {
"id": 115,
"name": "John Doe"
}
}
When I first learned about GraphQL, my thought was: this might be an advantage in some situations, but if you are using a XData REST server, it’s not a big difference. With XData, there are ways to get all related (associated) information in one single server request (roundtrip).
Schema introspection (Self-documentation)
As I’ve mentioned above, GraphQL is based on a schema which holds information about all types, fields and other elements needed to describe and validate a GraphQL query. Not only that, GraphQL itself provides a way for clients to retrieve information about such schema, a process called introspection. For example, this query will ask for all fields of the type Human, with their respective types:
{
__type(name: "Human") {
name
fields {
name
type {
name
kind
}
}
}
}
The query would return something like this:
{
"data": {
"__type": {
"name": “Human”,
"fields": [
{
"name": "id",
"type": {
"name": null,
"kind": "NON_NULL"
}
},
{
"name": "name",
"type": {
"name": null,
"kind": "NON_NULL"
}
},
{
"name": “homePlanet”,
"type": {
"name": "String",
"kind": "SCALAR"
},
{
"name": “height,
"type": {
"name": “Float,
"kind": "SCALAR"
},
{
"name": “mass”,
"type": {
"name": “Float”,
"kind": "SCALAR"
}
}
]
}
}
}
This brings a lot of benefits. First, all clients know in advance what information they can retrieve. That also means that a GraphQL server is self-documented, since the schema already describes what it can offer.
For a client to use a REST server, for example it necessarily needs to go to some kind of documentation, because the client simply don’t know that an invoice resource is available at some endpoint /invoice/:id, or what is the type of the id, or any other ways to create an invoice, different ways to query, etc. That’s not the case with GraphQL: everything is there.
Also, this makes it possible to create lots of tools around GraphQL. I will mention it later in this article.
Again, REST servers also have a nice way to provide meta information about it: Swagger. The problem, of course, is that not all REST servers implement Swagger. Also, some REST implementations require you to do lots of extra coding to properly build the Swagger file, like adding lots of attributes just to flag each endpoint, which parameters are available in each endpoint, etc.
Luckily, TMS XData does support Swagger beautifully, and in a very automatic way. Basically, after you created your REST API with XData, your Swagger document is provided automatically, because it has all metadata information from the interfaces declared as endpoints, thanks to the way XData is built. So the “introspection” of a XData REST server can be enabled with just a few lines to code, and available at a single endpoint:
https://myapi/openapi/swagger.json
Again, this is a nice GraphQL feature, but with proper tool or effort, REST servers can also provide such mechanism.
Versioning
From GraphQL website: Why do most APIs version? When there’s limited control over the data that’s returned from an API endpoint, any change can be considered a breaking change, and breaking changes require a new version. If adding new features to an API requires a new version, then a tradeoff emerges between releasing often and having many incremental versions versus the understandability and maintainability of the API.
In other words: it’s easier to expand and evolve a GraphQL API because clients never receive information that they didn’t ask for. Adding a new field to Human type, for example, will be harmless because existing clients will never receive that new field, because they never asked for it. On the other hand, adding a new field to a REST endpoint will result in a different response for existing clients (the new added field).
Thus, GraphQL makes it easier to evolve your API and, in theory – in most cases, not all – you don’t need to version your API.
Tools and libraries
In my opinion, this is where GraphQL really shines, and which justifies using it. As you saw, when you use nice libraries for building REST servers, like TMS XData, you kind of minimize the advantages of GraphQL over REST. The limitations of REST are known, and a good framework, over time, will add features to solve the problems. That’s what XData does.
But when you have an ecosystem, it’s a different thing. You can’t control or define everything that will be built around a tool or a specification. Since the release of GraphQL, lots of tools and libraries have been built, and once you have your GraphQL API, you can benefit from all of them.
This nice article describes 10 awesome tools and extensions for GraphQL APIs, and I will explicitly mention some of them here.
GraphiQL and/or GraphQL Playground
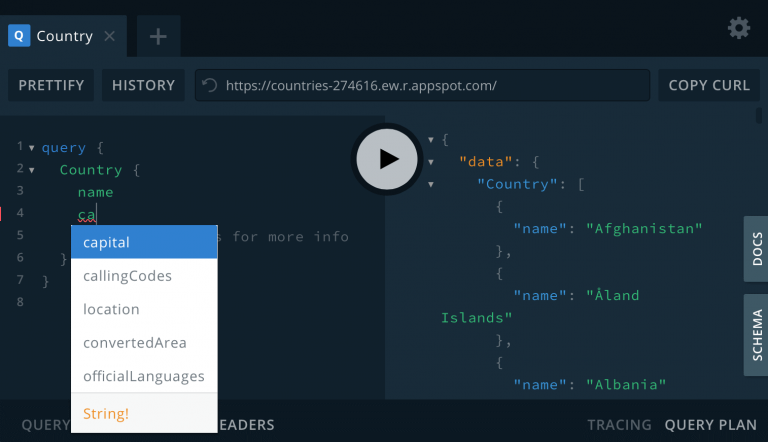
Simply put, GraphiQL and GraphQL Playground are a “GraphQL IDE”. From there you can write your queries with full code completion (GraphQL has a schema, remember?), syntax check, detailed error messages and positions, among others. It really makes it easy to write and run GraphQL queries.
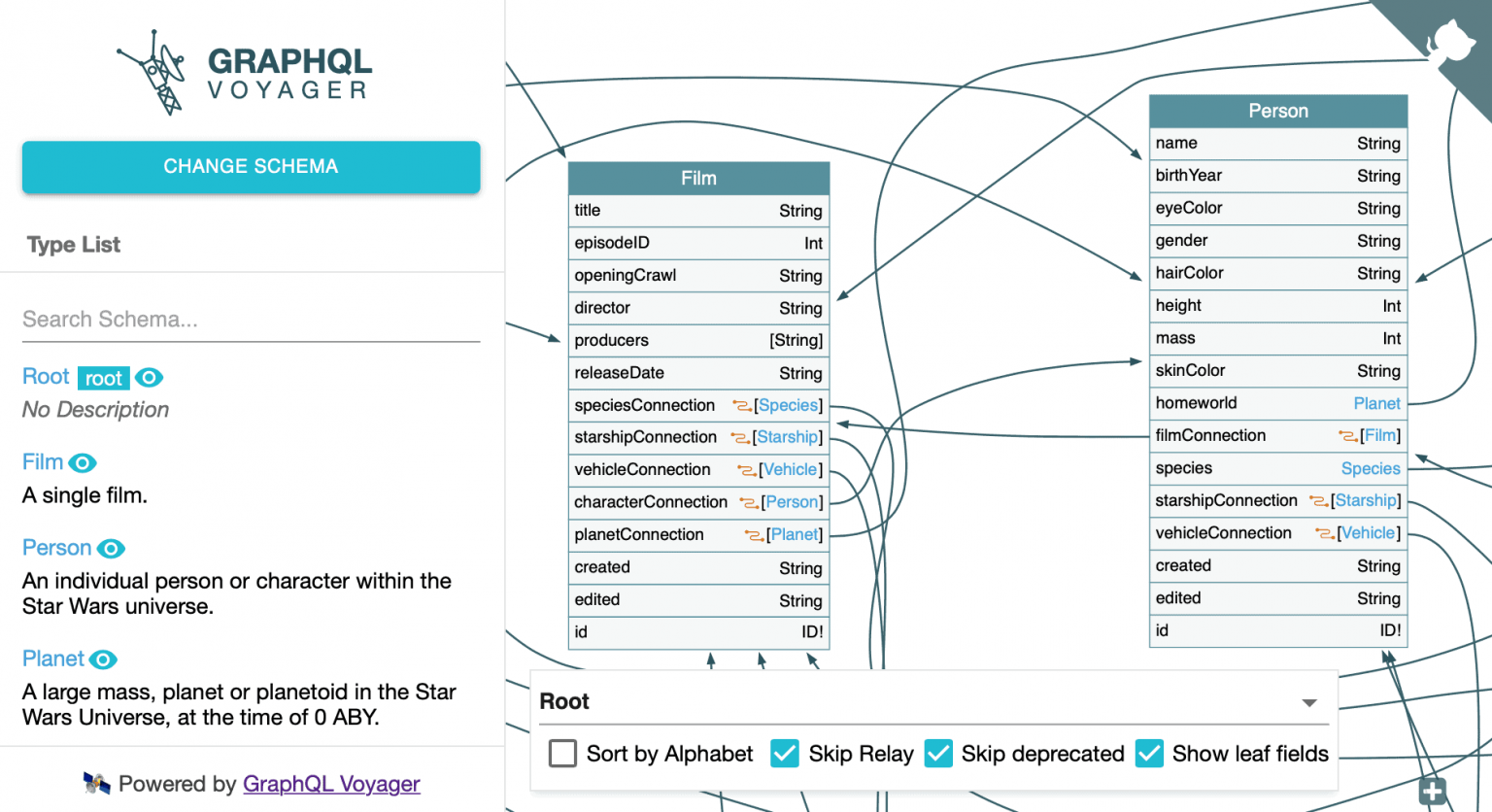
GraphQL voyager is a tool to represent any GraphQL API as an interactive graph. Another tool that takes advantage of the GraphQL schema introspection. You quickly see all your schema in a graphical way, and how each field and type relates to each other. It has a nice live demo you can try.
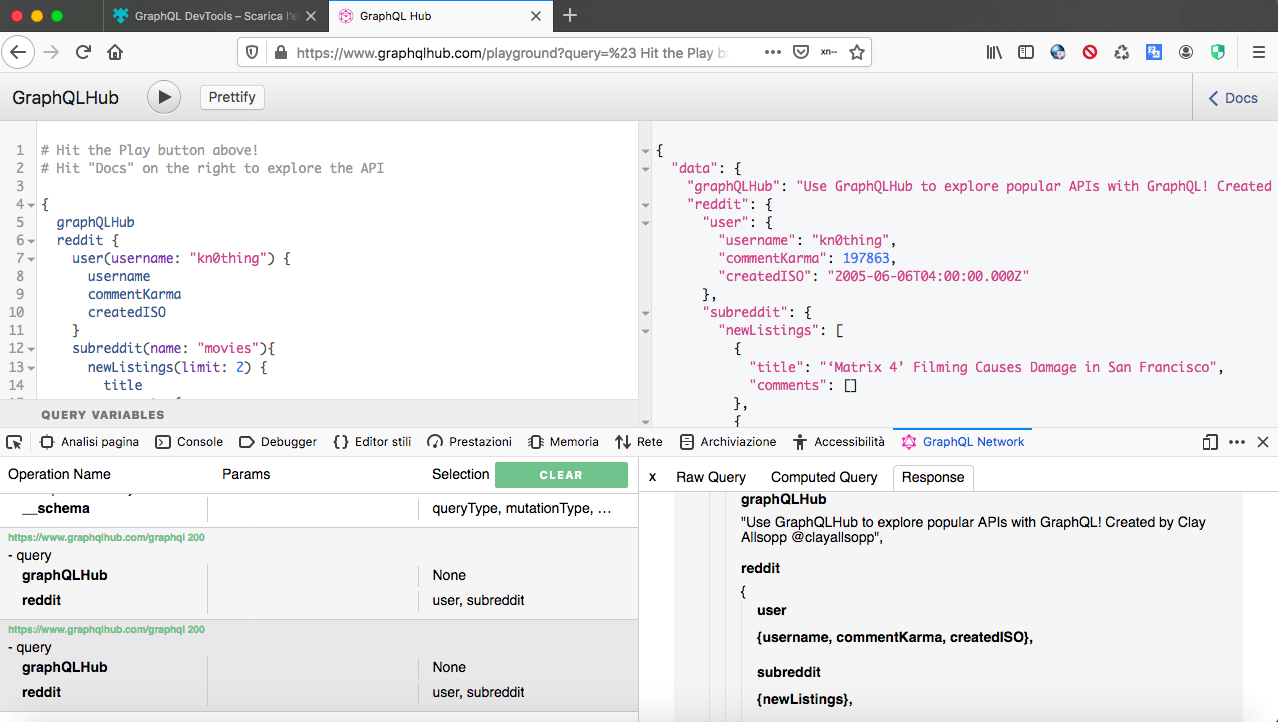
Browser extensions
There are several GraphQL extensions to your favorite browser that helps you out when building web applications that connect to GraphQL. Both Chrome GraphQL Network and Firefox GraphQL DevTools extensions are valuable tools that allows you to debug, inspect requests, track errors and increase your productivity when working with GraphQL. They are just honorable mentions, of course there are much more extensions for different purposes that you can use.
Clients all around
This deserves a separated article, but of course it’s worth mention that libraries for GraphQL clients are all around. If you want to build web or mobile applications, there are clients for React, VueJs, Angular, Swift, Kotlin, Flutter and many other development tools and libraries.
Final notes
I didn’t name this section “Conclusion” because there is nothing to conclude. This article also didn’t have an intention to compare GraphQL with anything – even when I do comparisons with REST here and there.
The idea was to introduce this technology to newcomers, and also for those who already knew about it, talk about it from the perspective of a Delphi developer, hoping that I had clarified some points that might be obscure for those used to Delphi – I tried to focused exactly on the points that got me confused when I started learning about GraphQL.
What about you? Do you have any experience with GraphQL? Are you using it in production? What do you think about it? Are you a newcomer and want to ask something or share your doubts? Please leave your comment following the link below and let’s discuss about it!